
DevOps for the Sinclair Spectrum - Part 3
Updated:
This article is part of a series
- Table Of Contents - Full table of contents in Part 1
- Part 1 - Introduction, hardware, development environment, Windows/Linux buildchain and tools
- Part 2 - The server environment and building the first prototype
- Part 3 - The backend server daemon, pipelines and unit tests
- Part 4 - Wrap-up, other sites and final thoughts
In Part 2 I discussed the server environment, as well as how I built and launched the first prototype version of the site. I hit some speedbumps along the way and quickly reached the limits of what I could do with a pure client-only 1980s BASIC codebase. In this part, I’ll look at how I moved to a backend API system and how all this is deployed and tested.
Backend
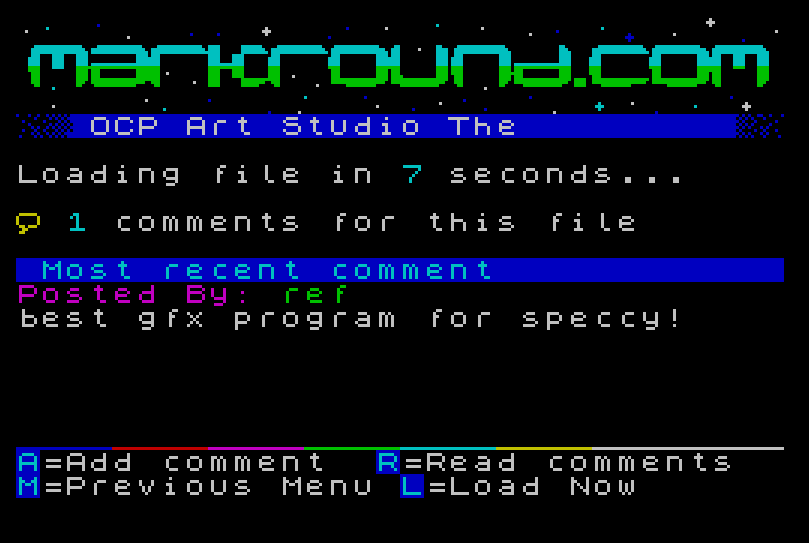
tnfsd that would do all the “heavy-lifting” and provide interactive features. This would let me shift some of the work that was too slow or difficult to do in BASIC to a domain I’m more familiar with. It also lets me do stuff that was simply impossible to do in a pure client-only model, like storing user data and so on. It’s time to get all client/server up in here…
The TCP Service
The Spectranet includes a streams extension for Sinclair BASIC, so you can use print and input statements on the Speccy to send and recieve data over a TCP Socket. As my weapon of choice for throwing together quick prototypes is Ruby (❤), I wrote a simple multi-client TCP Server using something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#!/usr/bin/env ruby
# Needed otherwise Spectranet blocks
$stdout.sync = true
require 'socket'
server = TCPServer.new(1234)
loop do
Thread.start(server.accept) do |client|
begin
request = client.gets
# process request
client.print("Hello, world!\n")
client.close
# Make sure that exceptions don't crash the whole server.
rescue Exception => e
puts "Error : Exception in server : #{e.class.name}\n#{e}"
client.print("\n")
client.close
next
end
end
end
Usage from BASIC
Accessing this server process from BASIC using the Spectranet extensions is really simple, you just have to do something like this to send a command and read the output into a variable v$:
1
2
3
4
%connect #5,"_API_SERVER_",_API_PORT_
print #5; "version"
input #5; v$
%close #5
I decided to keep things as simple as possible so built my own protocol using text-based stateless commands over this TCP connection and sent responses that could easily be parsed in Spectrum BASIC. I took inspiration from classic Unix protocols like finger and even HTTP which essentially just use a Telnet-like connection. I did much the same here although it is a strictly stateless, one-shot command/response per-connection affair:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
begin
request = client.gets
# These are sanitised later
(handler, params) = request.split(" ", 2)
params.chomp!
peer=client.peeraddr[2]
...
...
case handler
when 'status'
server_status(client)
when 'version'
version(client)
when 'list'
list_files(client, params)
...
...
end
# Clean up
client.print("_EOF_\n")
client.close
end
After a simple bit of request-routing, each “verb” is handled by a function in an included handler file. For example, the version command is implemented as:
1
2
3
def version(client)
client.print("#{VERSION}\n")
end
Note the _EOF_ sent at the end of the main function: That’s one of my protocol reserved words like _NEXT_ which I send to the Spectrum BASIC client to indicate pagination is required in a response.
Protocol development
I then added simple control-characters to include extra metadata in the response - things like indicating whether a given file has comments attached to it, or color-code indications for colorful text. Keeping it simple like this is a huge help when considering the almost non-existent support for string parsing in Speccy BASIC. So, on the server side to indicate if a file has comments, there’s a block of Ruby code that looks like this:
# Spectranet buffers for receiving data seem to be limited to 256 bytes.
# Build up the output, making sure adding each pair of lines doesn't go over 200 bytes
# If so, we stop, and send a _NEXT_ with the next start position
size=0
files[start,limit].each do |file|
title=File.basename(file, '.tap').gsub('_',' ')
# Check if there is extra data for the file
# % = comments
# # = top file (todo)
# & = both
if File.file?(comments_file)
title="%#{title}"
end
size += title.size + file.size
if size >= 200 then
client.print("_NEXT_\n")
return
end
client.print("#{title}\n")
client.print("#{file}\n")
endThen in BASIC, I connect to the service and list the files along with a comments icon if applicable:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@gameslist:
if start <= 0 then let start = 0
let more = 0
let c=17: gosub @clearscreen
gosub @connect
let s$=str$ start
print #4; "list dir=games,letter="+l$+",start="+s$
for n = 0 to count-1
input #4; d$
if d$ = "_NEXT_" then gosub @reconnect : input #4; d$
if d$ = "_EOF_" then let n = count-1: %close #4: goto @gameswfi
input #4; f$
if f$ = "_END_" then let n = count-1 : print at 16,0; "No more files" :
next n : let more = 0 : %close #4: goto @gameswfi
let i$ = str$ n
#' Icons for status
print at offset+n,0; paper 1; ink 5; i$; paper 0; ink 1; " .. "
if d$( to 1) = "%" then print at offset+n,3; ink 6; chr$ (144): let d$=d$(2 to len (d$))
print at offset+n,5; ink 7; d$
next n
let more = 1
gosub @close
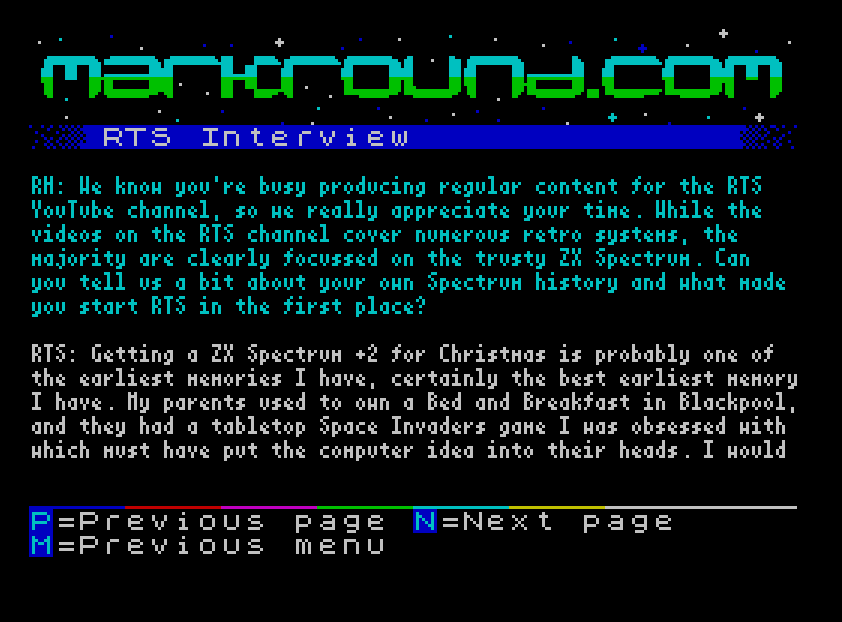
%. I also used this approach to send colour-control characters for my text-file viewer that’s used for the articles and “about” sections of the site. You can see an example in the adjacent screenshot; the light blue lines started with the %5characters indicating to my code that it should use pen #5 (Cyan) for the line of text.
Chunking
However, there is a catch with all this that doesn’t appear to be explicitly documented. It took me a long time to work this out with Wireshark dumps and lots of debugging, but it seems as though the Spectranet streams extension uses 256-byte buffers, and if the sent data overflows that, then a read via a BASIC INPUT will block forever.
So my API now has to split responses into under 256-byte chunks (After some testing, I picked 200 bytes allowing for future protocol overhead), and signal to the client that a response was chunked. The client then has to re-open the connection and request the next chunk which for some things now results in 2-3 connections before all the entries can be displayed. I’m going to continue work on this though and see if I can optimize it, but for now it’s working OK. You can see the _NEXT_ code for pagination being sent in the server Ruby code above, along with it being handled in the BASIC code on line 10.
Deployment
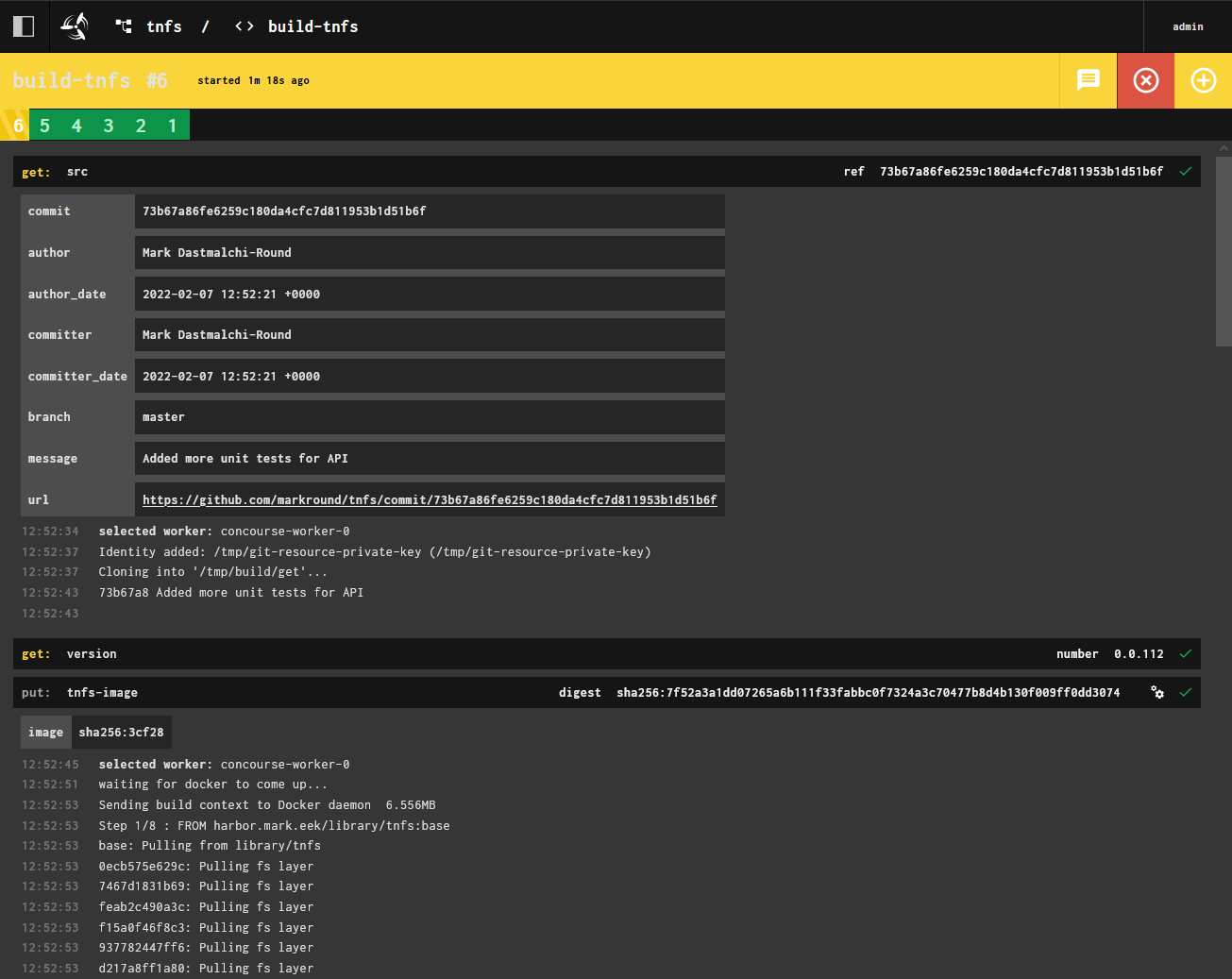
Since I wrote this article, I have switched to a stack that mostly consists of Drone for CI and Flux for deployment across my k8s clusters. I’ve found this to be a very effective combination of tools for deployment, and as I had written everything with containerization in mind I was able to port my old Concourse pipelines over with a minimum of hassle.
I make use of a few key Concourse resource types, mainly my patched docker-image-resource that accepts a Docker config.json for authentication against multiple private registries, and the
rsync resource for pushing static site and code updates to servers. For example, to define an OCI image resource for e.g. my tnfsd server container, I have something like this in my pipeline.yaml:
resources:
- name: public-tnfsd-image
type: docker-image-resource
icon: cloud-upload-outline
source:
tag: latest
email: ((docker-hub-email))
username: ((docker-hub-user))
password: ((docker-hub-password))
docker_config_json: ((docker-config-json))
repository: ((docker-hub-user))/tnfsdAnd this gets built and pushed to Docker Hub using a task like this:
- name: build-tnfsd
plan:
- get: tnfsd-source
trigger: true
- put: public-tnfsd-image
params:
build: tnfsd-source
tag_as_latest: trueAll these tasks are chained together using resources passed along them, and are set to trigger the concourse-git resource whenever a Git commit is pushed to the relevant branch.
One of the great things about adopting the GitOps approach is that I can develop on any system with a git client and text editor. I can even use my “alternative” OS systems like my X5000 running AmigaOS 4.1 which is conveniently located right next to my Speccy and other retro systems. I just commit and push my code, and in the background the infrastructure is updated and the site gets built, tested and deployed in seconds.
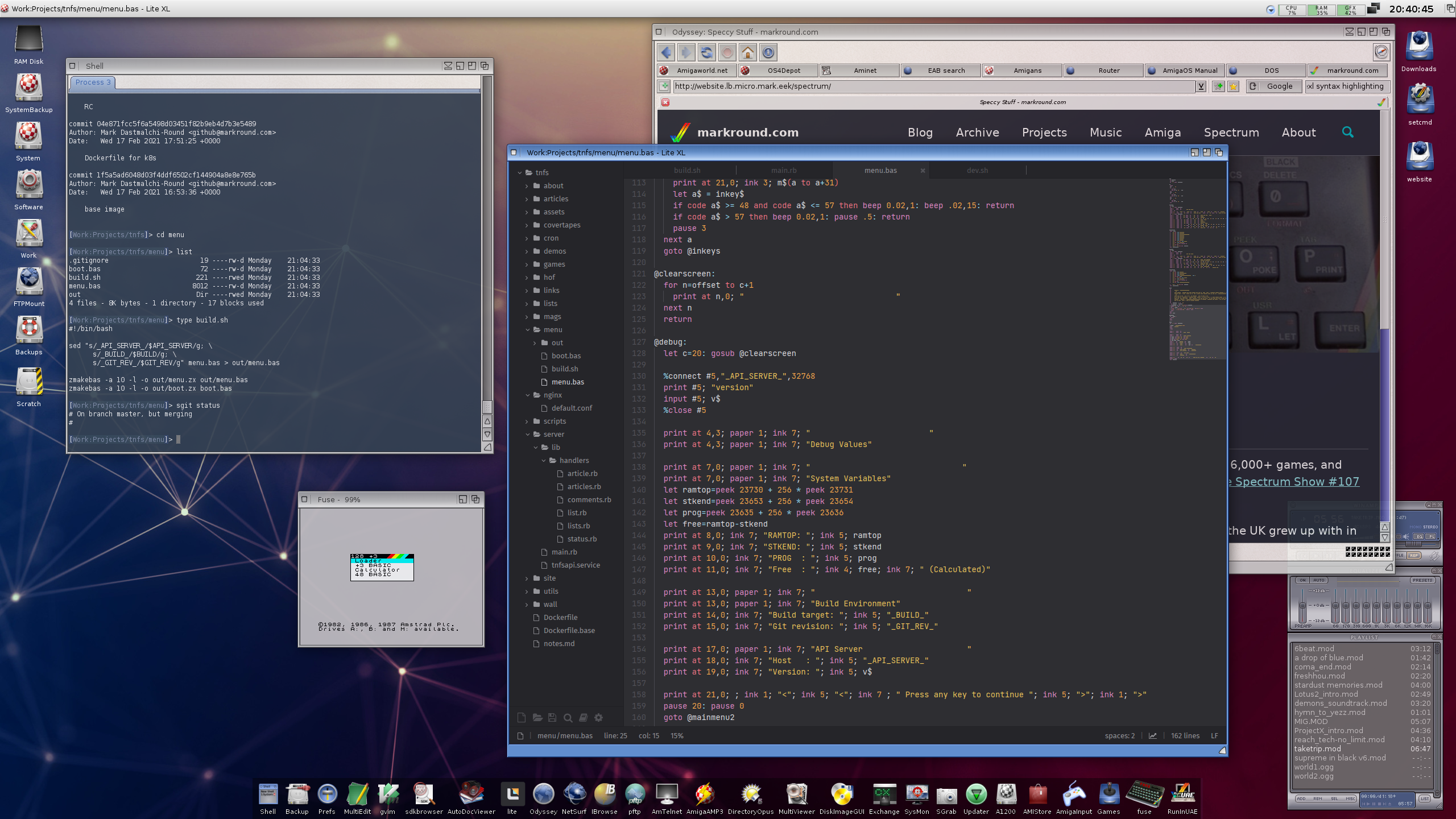
Note: In that screenshot above, I’m using the awesome LiteXL editor that has recently been ported to AmigaOS 4.x. On the remote chance that there’s anyone else using a next-gen Amiga system that also wants to write Spectrum BASIC code, I’ve created a rudimentary Lua plugin for it that does syntax highlighting.
Unit Tests
As I was going full-on into the whole GitOps thing, I figured I may as well go the whole hog and include automated tests in there! Testing is essential part of the software delivery pipeline and while it’s pretty difficult to do full graphical user-journey testing on an 8-bit micro, I could at least set up unit tests which have served me well in past projects like Tiller.

The ZX Printer

LPRINT command. Which is useful because amongst the many bits of old kit it emulates, FUSE includes ZX Printer support along with the ability to save the output to files on the host system. It does this through a sort of OCR system which works well enough to display the output from a BASIC program in plain text.
This gave me enough to build a crude but effective system: I run FUSE on a Linux system, booting from a .SZX snapshot state configured with Spectranet ROM. The emulated Speccy is configured to autoboot from a dedicated “unit test” TNFS server and FUSE captures the output from the program to a text file.
Unit Test environment
A command like the following takes care of launching FUSE, booting from Spectranet, enabling printer emulation and disabling audio output (useful inside containers):
$ fuse \
--snapshot snapshots/testing.szx \
--printer --zxprinter \
--textfile $PWD/output.txt \
--sound-device nullMy unit test TNFS server serves a boot.zx program which runs through a series of tests, and FUSE saves the “printed” output from this program to a file. To check for example, if the specified API server is responding as expected and if it returns a suitable minor x.y.z version number, an excerpt of my BASIC code (yes, Sinclair BASIC lacks an if/else construct!) looks like:
@status:
let n=n+1
gosub @connect
print #5; "status"
input #5; r$
gosub @close
lprint str$ n +":status API call:";
if r$="Server status is OK" then print "ok": return
if r$<>"Server status is OK" then print "failed": return
@version:
let n=n+1
gosub @connect
print #5; "version"
input #5; r$
gosub @close
lprint str$ n +":expected version API call:";
if r$(to 3)="1.3" then print "ok": return
if r$(to 3)<>"1.3" then print "failed": return
...
...This results in an “printed” text output file with test number, description and status code like the following:
11:status API call:ok
12:expected version API call:ok
...
...
All I had to do was save a copy of the expected correct results and use grep to check if those lines exist in the generated output from the test program. A simple shell script like the following does the “pass or fail” checking by returning a status code of 0(success) if all lines are present, and 1(failed) if anything is missing:
#!/bin/bash
set -e
output="${1:-output.txt}"
expected="${2:-expected.txt}"
while read line; do
egrep "^$line$" $output
done < $expectedPipeline integration
This can then be included in a Concourse task step, which allows the rest of the pipeline to continue as long as all tests pass. I’m working on properly containerising all this and have a proof-of-concept where FUSE is started with the aid of Xvfb. The printer output is written into a mapped volume which can be passed as an input to the next Concourse task in the unit-tests job. It’s all very hacky at the moment:
- The
ENTRYPOINTscript has to run FUSE through the coreutilstimeoutcommand, as there’s no way of auto-exiting FUSE when a program has finished running. I have to set a timeout slightly larger than my average test run time (30 seconds or therabouts) and tweak accordingly. - It currently requires privileged containers and host network access due to the Spectranet emulation.
- It’s very specific to my homelab e.g. the Spectranet snapshot has to be hard-coded to a specific TNFS server.
But it does work, and it definitely counts as one of my favourite creative hacks! If I manage to tidy it all up I’ll publish it somewhere as well.
Next
In Part 4 I’ll wrap up with my thoughts and reflections on this experiment, discuss my future plans and look at some of the other delighfully quirky TNFS sites out there. See you there…